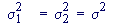|
Hypothesis testing
 Hypothesis Test
Hypothesis Test
Setting up and testing hypotheses is an essential part of statistical inference. In order to formulate such a test, usually some theory has been put forward, either because it is believed to be true or because it is to be used as a basis for argument, but has not been proved, for example, claiming that a new drug is better than the current drug for treatment of the same symptoms. In each problem considered, the question of interest is simplified into two competing claims / hypotheses between which we have a choice; the null hypothesis, denoted H0, against the alternative hypothesis, denoted H1. These two competing claims / hypotheses are not however treated on an equal basis: special consideration is given to the null hypothesis. We have two common situations:
The hypotheses are often statements about population parameters like expected value and variance; for example H0 might be that the expected value of the height of ten year old boys in the Scottish population is not different from that of ten year old girls. A hypothesis might also be a statement about the distributional form of a characteristic of interest, for example that the height of ten year old boys is normally distributed within the Scottish population. The outcome of a hypothesis test test is "Reject H0 in favour of H1" or "Do not reject H0".
Null Hypothesis
We give special consideration to the null hypothesis. This is due to the fact that the null hypothesis relates to the statement being tested, whereas the alternative hypothesis relates to the statement to be accepted if / when the null is rejected. The final conclusion once the test has been carried out is always given in terms of the null hypothesis. We either "Reject H0 in favour of H1" or "Do not reject H0"; we never conclude "Reject H1", or even "Accept H1". If we conclude "Do not reject H0", this does not necessarily mean that the null hypothesis is true, it only suggests that there is not sufficient evidence against H0 in favour of H1. Rejecting the null hypothesis then, suggests that the alternative hypothesis may be true. See also hypothesis test.
Alternative Hypothesis
The final conclusion once the test has been carried out is always given in terms of the null hypothesis. We either "Reject H0 in favour of H1" or "Do not reject H0". We never conclude "Reject H1", or even "Accept H1". If we conclude "Do not reject H0", this does not necessarily mean that the null hypothesis is true, it only suggests that there is not sufficient evidence against H0 in favour of H1. Rejecting the null hypothesis then, suggests that the alternative hypothesis may be true.
Simple Hypothesis
A simple hypothesis is a hypothesis which specifies the population distribution completely. Examples
See also composite hypothesis.
Composite Hypothesis
A composite hypothesis is a hypothesis which does not specify the population distribution completely. Examples
See also simple hypothesis.
Type I Error
In a hypothesis test, a type I error occurs when the null hypothesis is rejected when it is in fact true; that is, H0 is wrongly rejected.
The exact probability of a type II error is generally unknown. If we do not reject the null hypothesis, it may still be false (a type II error) as the sample may not be big enough to identify the falseness of the null hypothesis (especially if the truth is very close to hypothesis). For any given set of data, type I and type II errors are inversely related; the smaller the risk of one, the higher the risk of the other. A type I error can also be referred to as an error of the first kind.
Type II Error
A type II error is frequently due to sample sizes being too small.
A type II error can also be referred to as an error of the second kind. Compare type I error.
Test Statistic
A test statistic is a quantity calculated from our sample of data. Its value is used to decide whether or not the null hypothesis should be rejected in our hypothesis test. The choice of a test statistic will depend on the assumed probability model and the hypotheses under question.
Critical Value(s)
The critical value(s) for a hypothesis test is a threshold to which the value of the test statistic in a sample is compared to determine whether or not the null hypothesis is rejected. The critical value for any hypothesis test depends on the significance level at which the test is carried out, and whether the test is one-sided or two-sided. See also critical region.
Critical Region
The critical region CR, or rejection region RR, is a set of values of the test statistic for which the null hypothesis is rejected in a hypothesis test. That is, the sample space for the test statistic is partitioned into two regions; one region (the critical region) will lead us to reject the null hypothesis H0, the other will not. So, if the observed value of the test statistic is a member of the critical region, we conclude "Reject H0"; if it is not a member of the critical region then we conclude "Do not reject H0". See also critical value.
Significance Level
The significance level of a statistical hypothesis test is a fixed probability of wrongly rejecting the null hypothesis H0, if it is in fact true. It is the probability of a type I error and is set by the investigator in relation to the consequences of such an error. That is, we want to make the significance level as small as possible in order to protect the null hypothesis and to prevent, as far as possible, the investigator from inadvertently making false claims.
Usually, the significance level is chosen to be 0.05 (or equivalently, 5%).
P-Value
The probability value (p-value) of a statistical hypothesis test is the probability of getting a value of the test statistic as extreme as or more extreme than that observed by chance alone, if the null hypothesis H0, is true. It is the probability of wrongly rejecting the null hypothesis if it is in fact true. It is equal to the significance level of the test for which we would only just reject the null hypothesis. The p-value is compared with the actual significance level of our test and, if it is smaller, the result is significant. That is, if the null hypothesis were to be rejected at the 5% signficance level, this would be reported as "p < 0.05". Small p-values suggest that the null hypothesis is unlikely to be true. The smaller it is, the more convincing is the rejection of the null hypothesis. It indicates the strength of evidence for say, rejecting the null hypothesis H0, rather than simply concluding "Reject H0' or "Do not reject H0".
Power
The power of a statistical hypothesis test measures the test's ability to reject the null hypothesis when it is actually false - that is, to make a correct decision.
The maximum power a test can have is 1, the minimum is 0. Ideally we want a test to have high power, close to 1.
One-sided Test
A one-sided test is a statistical hypothesis test in which the values for which we can reject the null hypothesis, H0 are located entirely in one tail of the probability distribution. In other words, the critical region for a one-sided test is the set of values less than the critical value of the test, or the set of values greater than the critical value of the test. A one-sided test is also referred to as a one-tailed test of significance. The choice between a one-sided and a two-sided test is determined by the purpose of the investigation or prior reasons for using a one-sided test. Example
Two-Sided Test
A two-sided test is a statistical hypothesis test in which the values for which we can reject the null hypothesis, H0 are located in both tails of the probability distribution. In other words, the critical region for a two-sided test is the set of values less than a first critical value of the test and the set of values greater than a second critical value of the test. A two-sided test is also referred to as a two-tailed test of significance. The choice between a one-sided test and a two-sided test is determined by the purpose of the investigation or prior reasons for using a one-sided test. Example
One Sample t-test
A one sample t-test is a hypothesis test for answering questions about the
mean where the data are a random sample of independent observations from an
underlying normal distribution N(µ,
That is, the sample has been drawn from a population of given mean and unknown variance (which therefore has to be estimated from the sample).
Two Sample t-test
| |||||||||||||||||
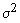 are specified
are specified
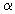
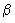 and written
and written